Hace unos días, @BiciBAD tuvo a bien compartir un fichero con datos de las estaciones del servicio de alquiler municipal de bicicletas de Madrid, BiciMAD. El archivo contiene registros a lo largo de algo más de un mes (desde el 16 de julio hasta el 22 de agosto) cada media hora. No tengo información sobre la forma en la que se ha obtenido, pero en algún momento me pareció ver en Twitter una conversación en la que @BiciBAD dejaba caer que es el resultado de preguntarle directamente al servidor del que toma los datos la aplicación móvil. Como digo, es una impresión mía y no tengo confirmación por su parte.
Me he puesto a jugar con estos datos en mis ratos libres para ver si era capaz de hacer algo similar a este análisis de las bicicletas de Seattle. Este artículo resume los análisis que he hecho.
Todo el código está disponible en este repositorio de github. Sigue, con alguna excepción mínima, el mismo orden que este texto. Excusatio non petita: el código publicado es un copia-pega de otro archivo más grande en el que tengo más análisis que todavía no he podido terminar. Tiene cosas francamente feas, pero funciona (lo he ejecutado del tirón antes de subirlo al repositorio).
Los datos incluyen cuántas bicicletas hay disponibles en cada estación, el número de anclajes libres, el número de bicicletas que están en su anclaje pero no pueden utilizarse y el número total de anclajes en la base. Esta definición de las variables es mi propia intuición a partir del nombre de cada una: el fichero de datos no venía con una descripción del contenido. No hay registros sobre qué bicicleta viaja a qué otra base. En resumen, los datos tienen este aspecto:
> head(bicis)
$oid available_bikes datetime free_spots id
1 55a7b8e269702d3199000000 5 2015-07-16 16:00:00 13 106a
2 55a7b8e269702d3199000001 16 2015-07-16 16:00:00 3 35
3 55a7b8e269702d3199000002 8 2015-07-16 16:00:00 15 118
4 55a7b8e269702d3199000003 9 2015-07-16 16:00:00 14 145
5 55a7b8e369702d3199000004 5 2015-07-16 16:00:00 12 15
6 55a7b8e369702d3199000005 10 2015-07-16 16:00:00 14 119
name station_available total_spots unavailable_bikes latitude
1 Colon A TRUE 18 0 NA
2 Pza. del Cordon TRUE 24 5 NA
3 Juan Martin TRUE 24 1 NA
4 Ortega y Gasset 87 TRUE 24 1 NA
5 S.Vicente Ferrer TRUE 21 4 NA
6 Mendez Álvaro TRUE 24 0 NA
longitude total_bikes
1 NA NA
2 NA NA
3 NA NA
4 NA NA
5 NA NA
6 NA NA
Aunque en ese listado inicial no aparezcan la latitud y longitud de cada estación, pueden obtenerse sin problemas (aparecen en registros posteriores; en las primeras entradas del archivo JSON no están registrados, por motivos que desconozco; supongo que a mitad de la recogida de datos se empezaron a añadir esos campos).
Una de las primeras cosas que se pueden ver es cuántas bicicletas están rotas (unavailable_bikes). Calculando este número como una fracción respecto a total_spots, queda algo así:

Como en esa imagen apenas puede distinguirse nada, aquí tienen un glorioso PDF. Se pueden observar varias tendencias:
- Hay estaciones con una proporción muy reducida de bicicletas rotas que se mantiene más o menos constante (Santa Engracia, Pza. Celenque, Pío Baroja, Castellana 42); y lo contrario, una proporción muy elevada (Antón Martín, Atocha A, Barceló).
- Estaciones en las que la proporción de bicicletas estropeadas va en aumento (Cabestreros, Santa Isabel). En alguna de ellas esa proporción ha subido inicialmente para darse la vuelta después (Augusto Figueroa, Pza. Santa Ana).
- Errores de lectura, supongo (Sevilla, Pza. Lavapiés).
Es posible que este análisis individualizado de las bicicletas que están rotas en cada estación le pueda ser de utilidad a alguien. Simplemente lo señalo para resaltar la utilidad que tendría el acceso libre a este tipo de datos.
En todo caso, lo que quería intentar era replicar el estudio original: hacer un análisis de componentes principales, comprobar si eso permite realizar una distinción entre el uso de BiciMad en días laborables y en fines de semana y ver cómo de diferentes son los patrones de esos dos grupos. En este caso, al contrario que en el conjunto de datos de Seattle, hay información de pocos días (38) y muchas bases (165).
Básicamente he creado la misma matriz de datos que en el análisis original (días en filas, estaciones por hora en columnas) y he sacado los dos primeros componentes principales. Como aquí no tengo exactamente la información de cuántos viajes han partido de cada base en cada instante temporal, utilizo en su lugar la variable available_bikes, que dice (o intuyo que dice, como comenté antes) cuántas bicicletas hay disponibles en la estación en ese momento; creo que puede dar resultados similares. Y, efectivamente:
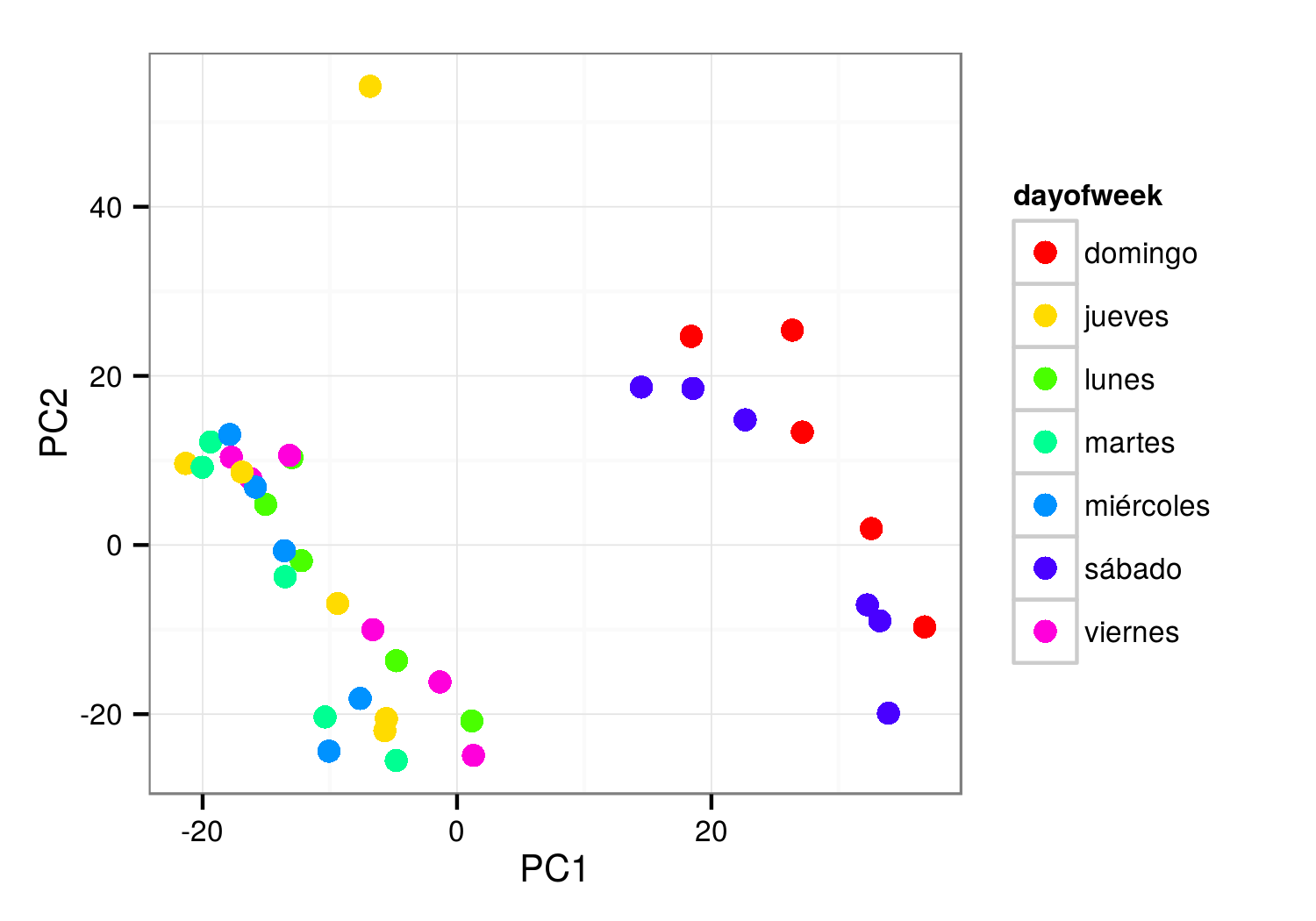
Como en el análisis de Seattle, los domingos y los sábados está en su propio cluster, y los días laborables van por otro lado. El punto raro de arriba es el primer día de la serie, el 16 de julio, que solamente tiene datos a partir de cierta hora.
En este caso es trivial separar los datos en dos grupos. Si dibujo la trayectoria del fin de semana por una parte y los días laborables por otra (sumando las bicicletas disponibles en todas las estaciones), debería quedar algo como...
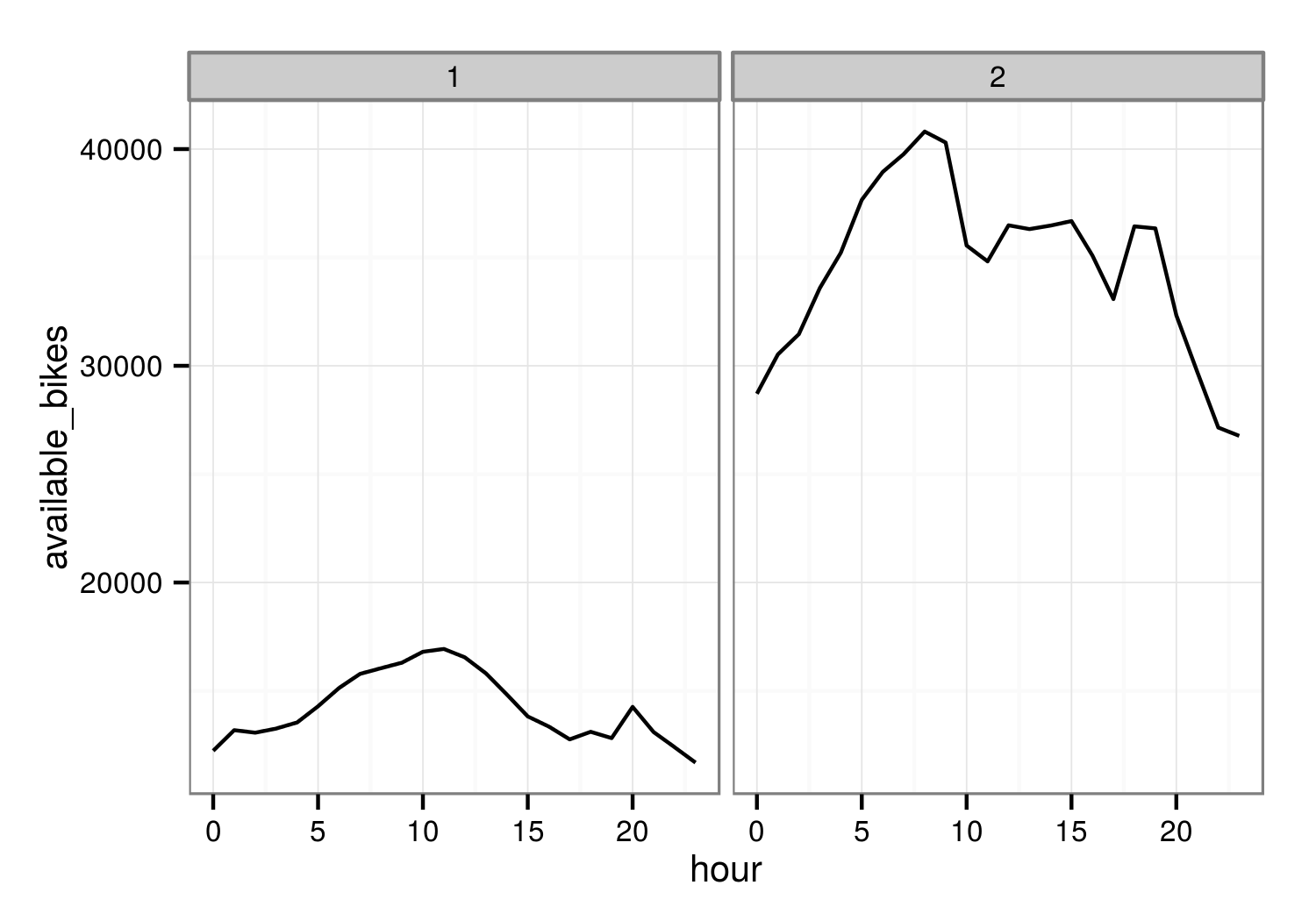
¡Ooops! No esperaba esto, sino algo así. El patrón del fin de semana es correcto, pero el de los días laborables no muestra el viaje de por la mañana y de por la tarde.
{kind=link}
De todas formas había dicho antes que este problema no era igual al original porque aquí hay información de muchas más bases; en Seattle simplemente estaba la base este y la base oeste. Y también hay que tener en cuenta que las bicicletas que salen de una estación tienen que terminar en otra. Igual reduciendo el número de estaciones sale algo más razonable. Se puede mirar, por ejemplo, qué ocurre en Puerta de Toledo:
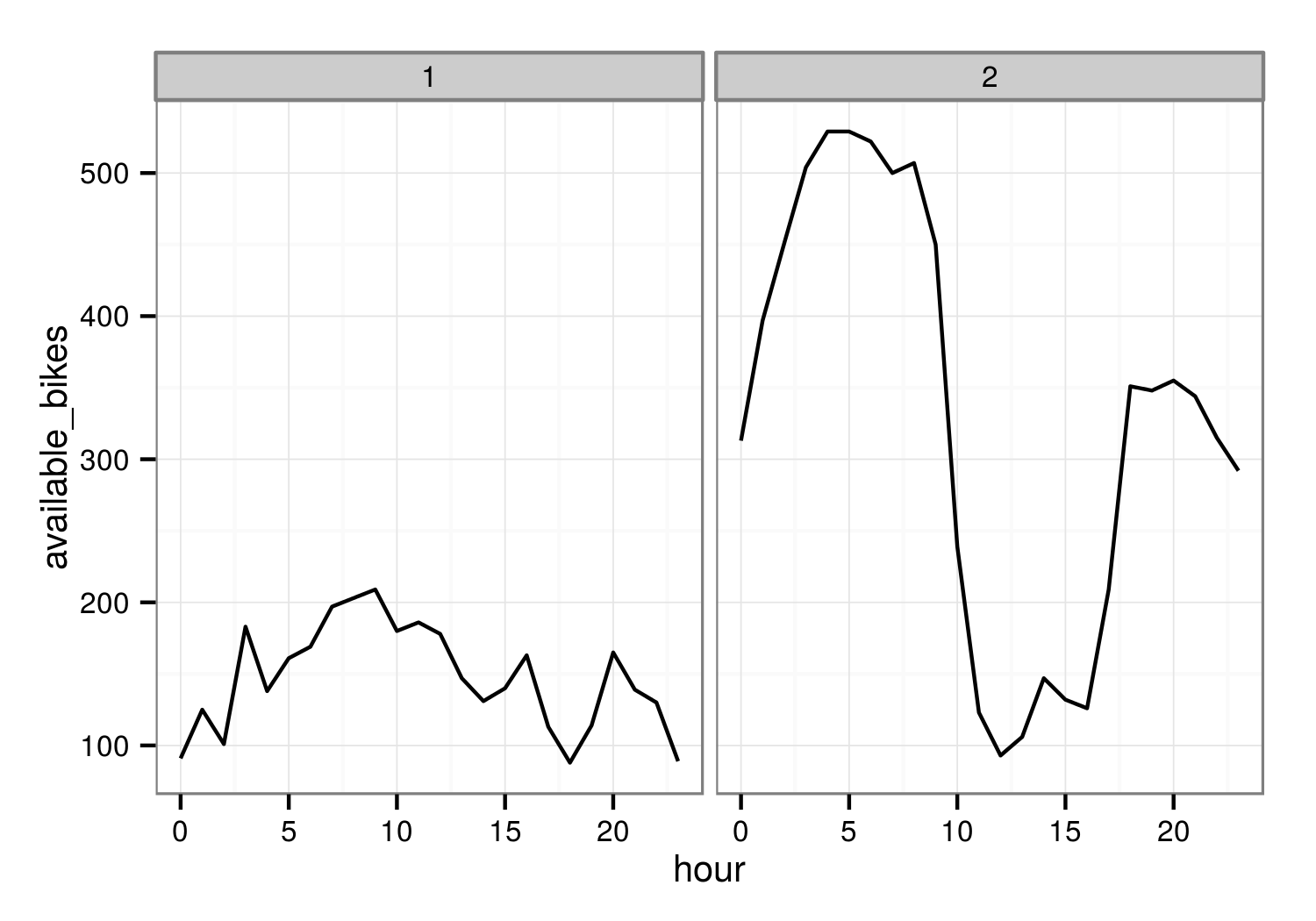
Esto ya se parece bastante más. Esta estación tiene muchas bicicletas por las noches, pero durante el día comienzan a utilizarse (más o menos coincidiendo con el comienzo de la jornada laboral) y se empieza a vaciar; por la tarde comienza a llenarse otra vez pero a eso de las 19:00 - 20:00 se vuelven a coger unas cuántas. Tiene sentido.
¿Entonces qué es lo que ocurre para que el patrón de los días laborables salga tan distinto a Seattle? Al mirar qué estaciones son más parecidas (correlan más) con Puerta de Toledo se obtiene esto:
# Y ese 0.45, sí, está puesto para que me salgan unas cuantas # estaciones y poder promediar mejor los resultados luego. > names(cor_to_ptol[cor_to_ptol > 0.45]) [1] "Cabestreros" "Conde de Casal" "General Yague" [4] "Juan Martin" "Maria Francisca 1" "Palos de la Frontera" [7] "Paseo Delicias" "Paseo Esperanza" "Pedro Bosch" [10] "Puerta de Granada" "Puerta de Toledo" "Pza. S.Francisco" [13] "Ribera de Curtidores" "Sta. Mª de la Cabeza"
¿Y habrá algunas que vayan al contrario?
> names(cor_to_ptol[cor_to_ptol < -0.45]) [1] "Antonio Maura" "Banco de España A" [3] "Banco de España B" "Castellana" [5] "Castellana frente Hnos. Pinzon" "Cibeles" [7] "Columela" "Goya Colon" [9] "Ortega y Gasset" "Puerta del Angel Caido" [11] "Serrano"
Si se agrupan estos dos comportamientos opuestos y se dibuja lo que ocurre en ellos (de media) entre el 20 de julio (lunes) y el 24 de julio (viernes), se obtiene lo siguiente:
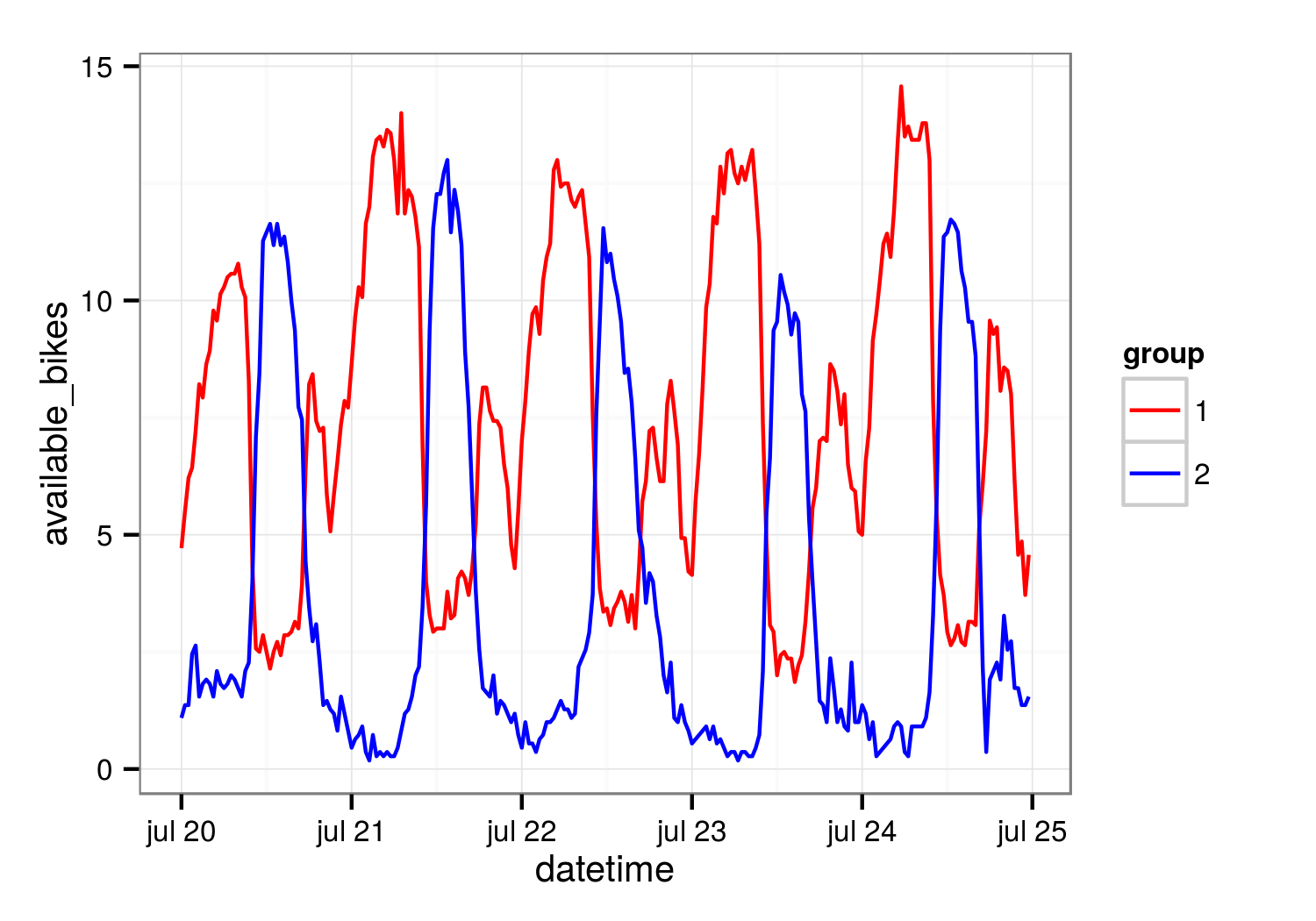
Las estaciones de una parte de la ciudad siguen el patrón antes descrito, que podría corresponderse con el típico de una zona residencial. Otras van al revés, reciben bicicletas durante el día y se quedan vacías por las noches (y no tienen ese segundo valle vespertino): es una zona más comercial y de oficinas. Las estaciones del grupo 1 se encuentran en zonas más de vivir (asequibles, si lo prefieren) que las del grupo 2 (fuente: encuesta muy informal en mi Twitter).
Si alguien quiere ver aquí una división de la ciudad en zonas de distinto perfil socioeconómico, allá usted. Pueden unirse a mi sospecha de que el habitante tipo de Serrano no coge la bicicleta para ir a trabajar. En todo caso, para poder afirmar eso necesitaría datos adicionales.
Y de momento hasta aquí he llegado. BiciMAD debería publicar un API de consulta en tiempo real de datos (y, gracias al buen hacer de un puñado de personas, ya sabemos que en el Ayuntamiento tienen constancia) y mucha más gente podría estar haciendo análisis como este. Mejor aún: gente con conocimientos de movilidad urbana podría estar haciendo análisis de estos datos.
(Agradecimientos a Txema Campillo, Iván Sánchez Ortega y las personas que respondieron veloces a mi mini-encuesta).